AI, Machine Learning & Deep Learning contd’
Explored Making Machine Learning Based Application
- Basic Image Classifiers using
- Pre Trained Models available by Google Deep Learning ML Library
- Created and Trained Deep Learing Models using H2O , a popular library
- SAP HANA Integration with External Machine Learning Technical Architecture
Concluded
- Deep Learning Model Training is computationally expensive
- Recommended / should only use GPU based infrastructure , Google and AWS provide prebuilt images or create your cloud image if not personal laptop to save $
Now, Briefly Explore
- Why Keras, another popular library for Machine Learning using TensorFlow
- Use of Existing Pre-trained Models for creating new models
- How to Make Your Models available as API for others to consume
- SAP HANA can make REST/ API call to get predictions
- “Why Should I Trust Machine learning ?” Explaining the Predictions of Any Classifier
- Use of LIME (Local Interpretable Model-Agnostic Explanations)
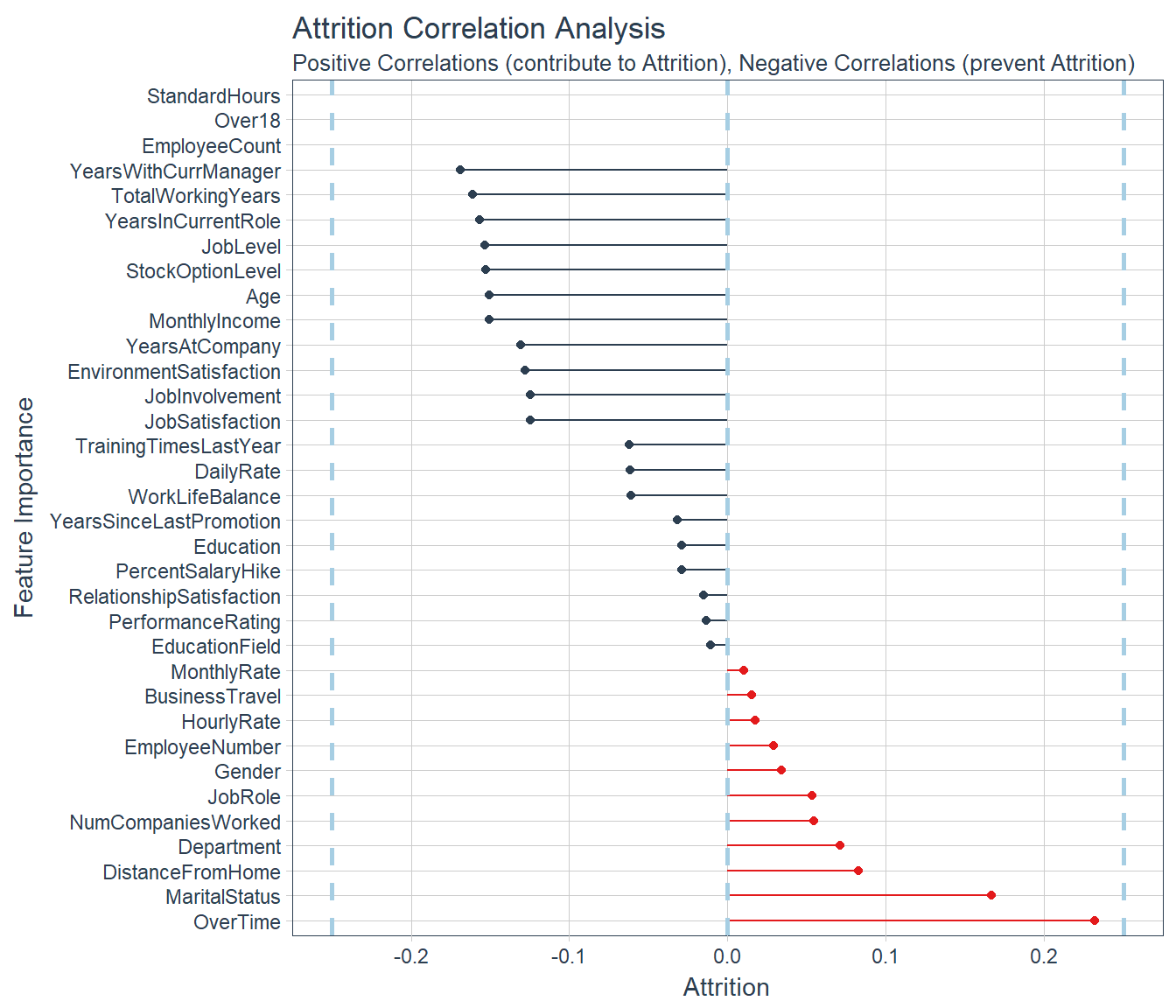
- Check Explanations With Correlation Analysis
- Provide simple explanation on interpreting the classification prediction with varibles used to predict
- Creation of Employee Turnover Prediction Machine Learning Model to illustrate above points
Why Keras
There are many deep learning frameworks available, however
- Keras supports multiple ecosystems engines
- The TensorFlow backend (from Google)
- The CNTK backend (from Microsoft)
- The Theano backend
- Amazon is also currently working on developing a MXNet backend for Keras
- Allows build on one and deployment on another backend, model on TensorFlow Model Server can be intgerated with SAP HANA using gRPC protocol
SAP HANA Integration with External Machine Learning Technical Architecture

Pre-Trained Models
There are alternatives to Google ML platform & hence potential cost saver, either start from scratch and train your own model or use pre-existing and fine tune upon these
- Many image classification models (with weights trained on ImageNet) are available
- Let’s see how the pre-trained model, for exapmple VGG16 Model based on CNN (Convolutional Neural Network or Convnets Model)work on to identify following image

## class_name class_description score
## 1 n01871265 tusker 0.64476359
## 2 n02504458 African_elephant 0.31524000
## 3 n02504013 Indian_elephant 0.03515862While TensorFlow models are typically defined and trained using Python or R code. One can deploy TensorFlow models in many environments without any runtime dependency on R or Python.
Make Your Models available as API for others to consume
- TensorFlow Serving is an open-source software library for serving TensorFlow models using a gRPC interface.
- SAP HANA can make http API call to get predictions using these models
Example of Model running on local server accessible and available to clients using web API call using JSON format for input data

Can you Trust Prediction of a Machine/Deep Learning Algorithm ?
Deep Learning models and even Machine Learning random forest models are difficult to explain in terms of what input features are influencing the predicted outcome. Sometimes, it is equally important to know why one should not trust the model before putting the model to use for false inferences, for example chocolate consumption does not result in winning Nobel Laurels awards, eventhough the most chocolates are consumed in the countries of the award winners !
- Measure Accuracy of Predictions
- Understand why any Classifier is making and contributing to the Prediction
- Use of Local(features values in the Neighbourhood of prediction) Interpretable Model Agnostic Explanations
- Use of Global values of Co-relations of Features to Outcome
- Get Insights into the Model
Employee Turnover Prediction
The key to success in any organization is attracting and retaining top talent. Losing high performimg employees not only causes loss in productivity but increase in cost in recruitement, training and loss in many other non tangible areas.
Use Deep Learning Artificial Intelligence Exercise to predict and explain turnover in a way that managers could make better decisions and executives would see desired results.
Using Sample Employee Data Source:
| Attrition | Age | BusinessTravel | DailyRate | Department | DistanceFromHome | Education | EducationField | EmployeeCount | EmployeeNumber | EnvironmentSatisfaction | Gender | HourlyRate | JobInvolvement | JobLevel | JobRole | JobSatisfaction | MaritalStatus | MonthlyIncome | MonthlyRate | NumCompaniesWorked | Over18 | OverTime | PercentSalaryHike | PerformanceRating | RelationshipSatisfaction | StandardHours | StockOptionLevel | TotalWorkingYears | TrainingTimesLastYear | WorkLifeBalance | YearsAtCompany | YearsInCurrentRole | YearsSinceLastPromotion | YearsWithCurrManager |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yes | 41 | Travel_Rarely | 1102 | Sales | 1 | 2 | Life Sciences | 1 | 1 | 2 | Female | 94 | 3 | 2 | Sales Executive | 4 | Single | 5993 | 19479 | 8 | Y | Yes | 11 | 3 | 1 | 80 | 0 | 8 | 0 | 1 | 6 | 4 | 0 | 5 |
| No | 49 | Travel_Frequently | 279 | Research & Development | 8 | 1 | Life Sciences | 1 | 2 | 3 | Male | 61 | 2 | 2 | Research Scientist | 2 | Married | 5130 | 24907 | 1 | Y | No | 23 | 4 | 4 | 80 | 1 | 10 | 3 | 3 | 10 | 7 | 1 | 7 |
| Yes | 37 | Travel_Rarely | 1373 | Research & Development | 2 | 2 | Other | 1 | 4 | 4 | Male | 92 | 2 | 1 | Laboratory Technician | 3 | Single | 2090 | 2396 | 6 | Y | Yes | 15 | 3 | 2 | 80 | 0 | 7 | 3 | 3 | 0 | 0 | 0 | 0 |
| No | 33 | Travel_Frequently | 1392 | Research & Development | 3 | 4 | Life Sciences | 1 | 5 | 4 | Female | 56 | 3 | 1 | Research Scientist | 3 | Married | 2909 | 23159 | 1 | Y | Yes | 11 | 3 | 3 | 80 | 0 | 8 | 3 | 3 | 8 | 7 | 3 | 0 |
| No | 27 | Travel_Rarely | 591 | Research & Development | 2 | 1 | Medical | 1 | 7 | 1 | Male | 40 | 3 | 1 | Laboratory Technician | 2 | Married | 3468 | 16632 | 9 | Y | No | 12 | 3 | 4 | 80 | 1 | 6 | 3 | 3 | 2 | 2 | 2 | 2 |
| No | 32 | Travel_Frequently | 1005 | Research & Development | 2 | 2 | Life Sciences | 1 | 8 | 4 | Male | 79 | 3 | 1 | Laboratory Technician | 4 | Single | 3068 | 11864 | 0 | Y | No | 13 | 3 | 3 | 80 | 0 | 8 | 2 | 2 | 7 | 7 | 3 | 6 |
Machine Learning Model Automation
Used Training and Cross Validation data from the source data for Machine Learning. Typically pre-processing and feature engineering is done at this stage , however with deep learning models these aspects are learnt by the model itself.
Model Accuracy using Confusion Matrix
Let’s see how often model correctly predicted true Attrition and false Attrition i.e. if actually there was a turnover and model predicted it correctly and if actually there was Not a turnover and model predicted it correctly , this time as no turnover. These two cases are commonly referred as True Positives and True Negatives. Converse of these cases are False Positives and False Negatives where model incorrectly predicted turnover , when there’s none or predicted no turnover where there’s one .
One way to consider Model accuracy when True Positive and True Negatives are high and False Positives and False Negatives are low values.
USing sample test data to determine accuracy of model
| No | Yes | |
|---|---|---|
| No | 161 | 21 |
| Yes | 10 | 19 |
In Our example, since Organizations would not like to lose Employees, Attrition value of NO is desired effect.
Precision is when the model predicts yes, how often is it actually yes. Specifity or Recall (also true positive rate) is when the actual value is yes how often is the model correct.
Incorrectly classify employees ,who are actually not looking to quit as high potential of quiting is still OK but classifying those employees that are likely to quit as not at risk shall not be considered Ok. It is important to not miss at risk employees. Also when the actual value of Attrition is YES how often the model predicts YES.
| accuracy | misclassification_rate | recall | precision | null_error_rate |
|---|---|---|---|---|
| 0.8530806 | 0.1469194 | 0.6551724 | 0.475 | 0.7630332 |
Recall for our model is 65.52 %. In an HR context , if Organization lose say 100 employees than this 65.52 % of employees could potentially be targeted with corrective measures to retain prior to their quiting.
How do Organizations decide what measures to implement to retain employees ?
Which Features are contributing to Attrition or No Attrition for first three cases
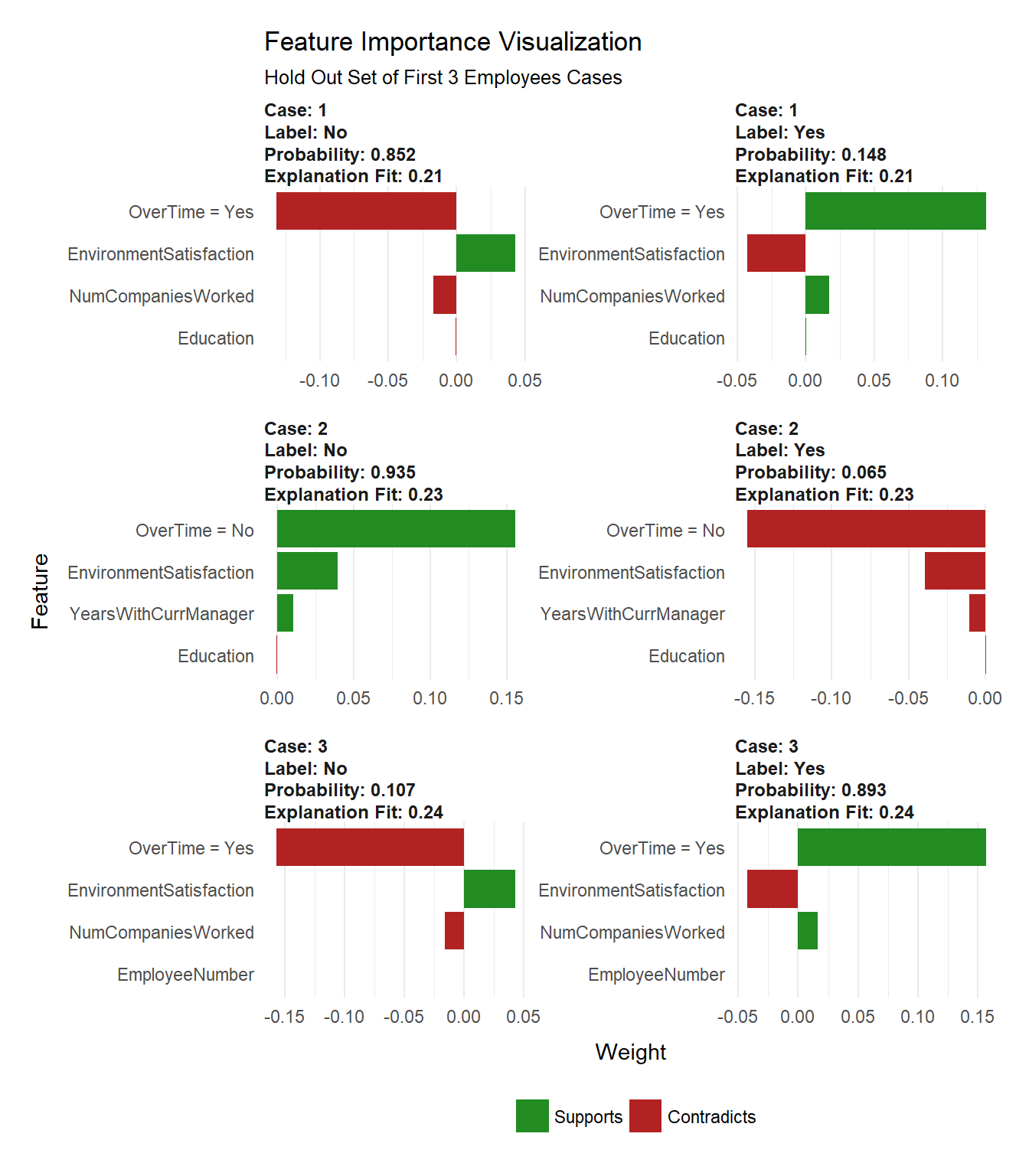
Features Importance for first three cases
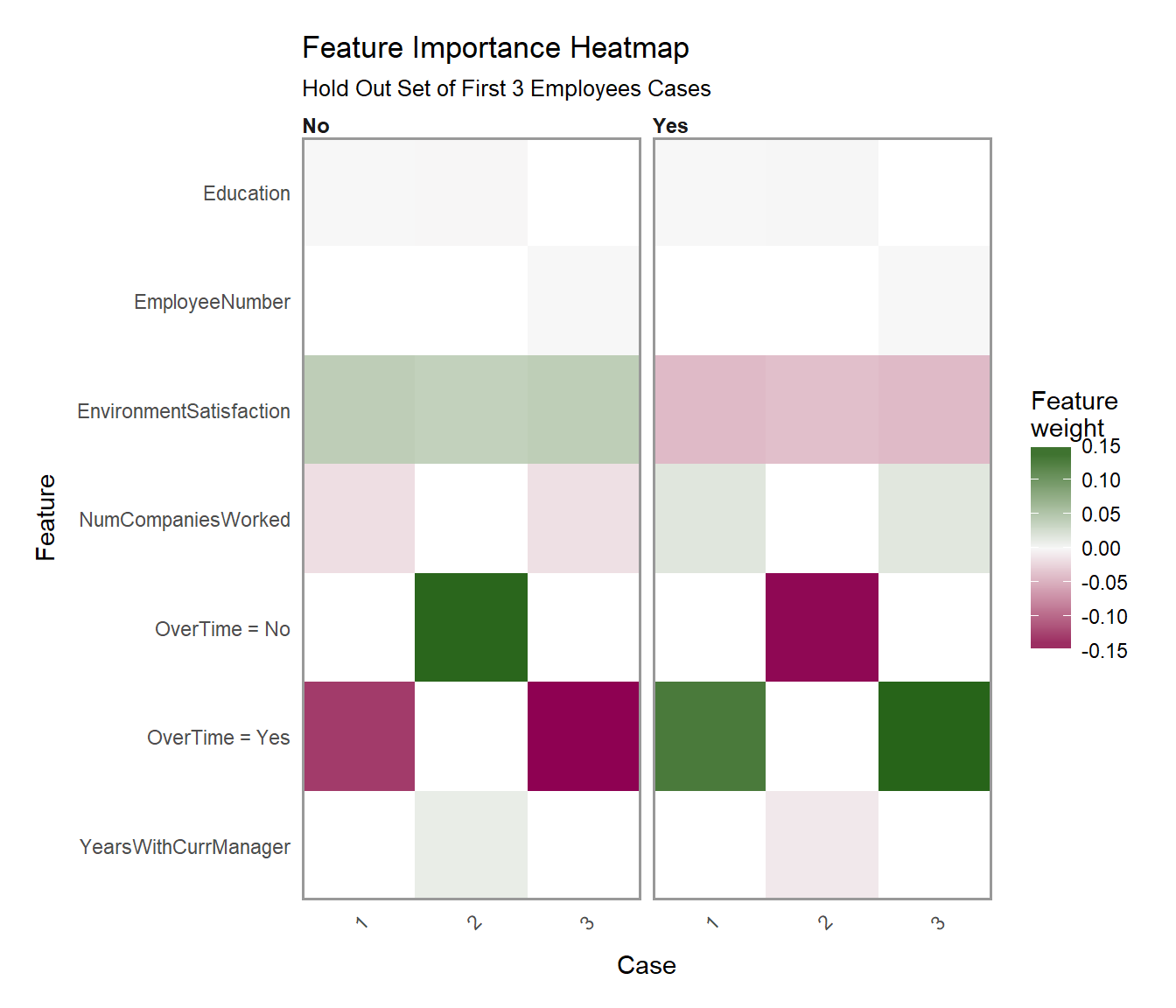
What features are important from a global perspective